
HASOC (2023)
Hate Speech and Offensive Content Identification in English and Indo-Aryan Languages
Hate Speech and Offensive Content Identification in English and Indo-Aryan Languages
Call for Participation
Task 2: Identification of Conversational Hate-Speech in Code-Mixed Languages (ICHCL)
A conversational thread can also contain hate, offensive, and profane content, which is not apparent from a standalone or single tweet or comment or the reply to a comment, but can be identified if given the context of the parent content.
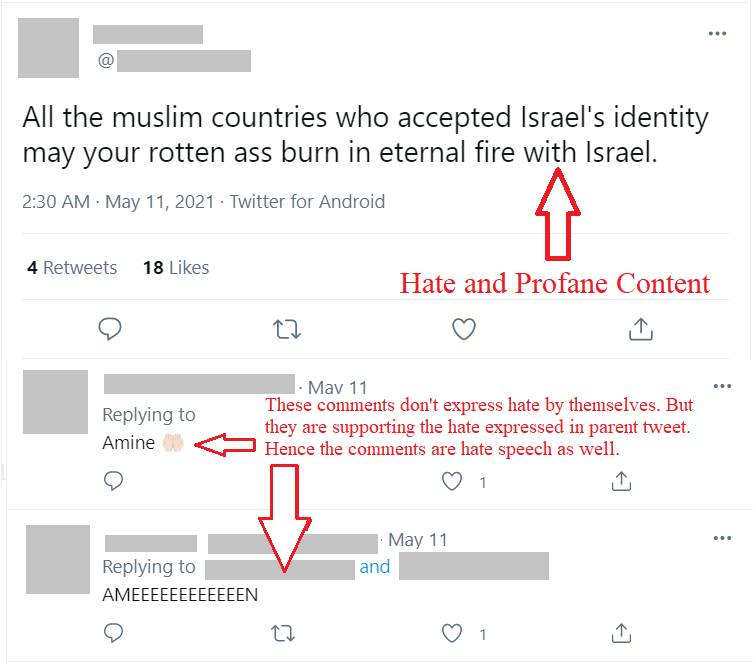
The above screenshot from Twitter describes the problem at hand effectively. The parent/source tweet, which was posted at 2:30 am on May 11th, expresses hate and profanity towards Muslim countries regarding the controversy happening during the recent Israel-Palestine conflict. The 2 comments on the tweet have written "Amine", which means trustworthy or honest in Arabic. If the 2 comments were to be analyzed for hate or offensive speech without the context of the parent tweet, they wouldn’t be classified as hate or offensive content. But if we take the context of the conversation, then we can say that the comments support the hate/profanity expressed in the parent tweet. So those comments are labelled as hate/offensive/profane.
This sub-task focused on the binary classification (task 2) of such conversational tweets with tree-structured data into:
• (NOT) Non Hate-Offensive - This tweet, comment, or reply does not contain any Hate speech, profane, offensive content.
• (HOF) Hate and Offensive - This tweet, comment, or reply contains Hate, offensive, and profane content in itself or supports hate expressed in the parent tweet
Furthermore, this year for the Hinglish language, we’re introducing a multiclass task (task 2b) that further divides the HOF tweets into 3 subclasses:
• (SHOF) Standalone Hate - This tweet, comment, or reply contains Hate, offensive, and profane content in itself.
• (CHOF) Contextual Hate - Comment or reply is supporting the hate, offense and profanity expressed in its parent. This includes affirming the hate with positive sentiment (example-2). and having apparent hate (example-3).
• (NONE) Non-Hate -This tweet, comment, or reply does not contains Hate, offensive, and profane content in itself.
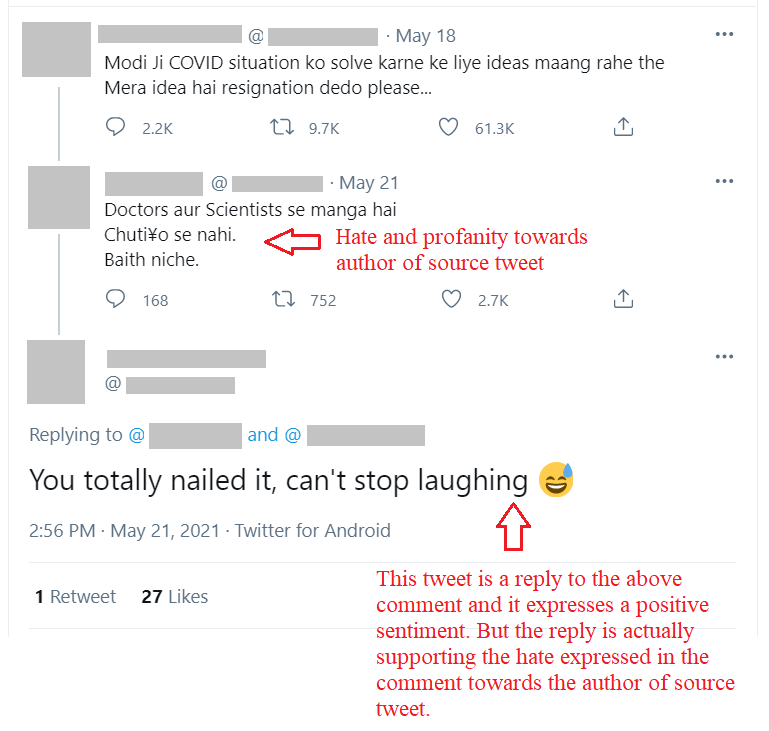
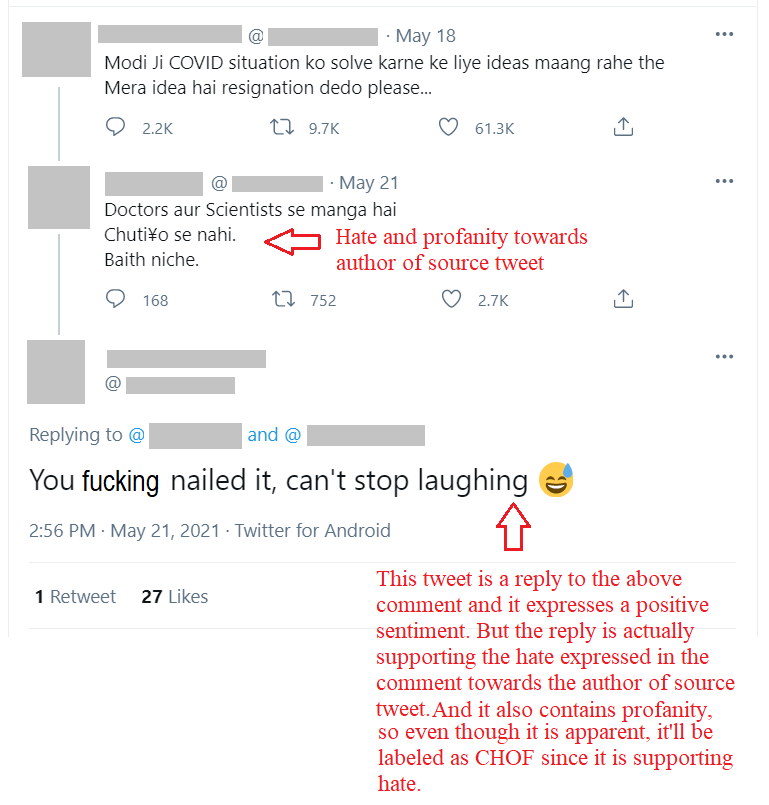
Another such example with code mixed text.
• The Source Tweet: Modi Ji COVID situation ko solve karne ke liye ideas maang rahe the. Mera idea hai resignation dedo please...
• Translation: Modi ji (PM of India) was asking for ideas to solve the covid situation of India. My idea to him is to resign.
• The Comment: Doctors aur Scientists se manga hai. Chutiyo se nahi. Baith niche. [HOF/SHOF]
• Translation: They have asked Doctors and Scientists. Not fuckers. Sit down. [HOF/SHOF]
• The reply: You totally nailed it, can’t stop laughing. [HOF/CHOF]
The reply has a positive sentiment. But it is positive in favour of the hate expressed towards the author of the source tweet in the comment. Hence, it is supporting the hate expressed in the comment. Hence, it is also hate speech.
This is the type of problem we’re aiming to solve via this shared task.
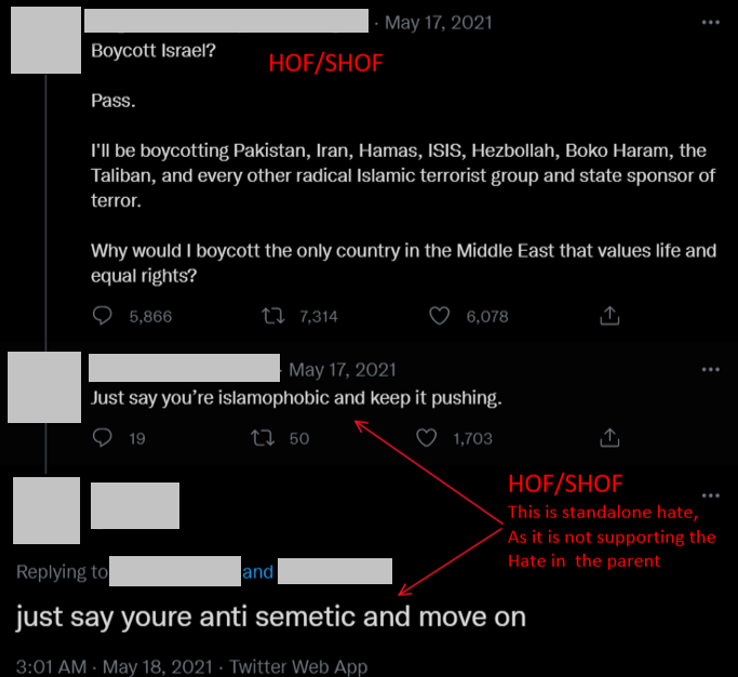
In the above (example-4), the main tweet portrays hate against a religion. Meanwhile, the comment is hateful against the author of the tweet. And not supporting the hate that was expressed in the main tweet. This is an example of 2 levels having standalone hate.
ICHCL Dataset & Baseline
We understand that FIRE hosts so many beginner friendly workshops every year and this problem might not seem like beginner friendly. So, we’ve decided to provide participants with a baseline model which will provide participants with a template for steps like importing data, preprocessing, featuring and classification. And the participants can make changes in the code and experiment with various settings.This baseline uses a pseudo labelling. approach.
Note: Datasets are password protected, please register to get access to passwords, once register you'll receive passwords from noreply.hasoc@gmail.com, in case if you have not received passwords after registration please check your spam, please reachout to us via hasocfire@googlegroups.com in case if any queries
Results
Important Dates
Timeline:
All subtracks have an independent timeline for training/test data release and run submission which will be available on respective websites. Here are the common timelines:
15th July
Training data release
15th August
Test set release and run submissions start
23th August
Registration deadline
29th August
Deadline for run submissions
31st August
Results announcement
20th September
Paper submission deadline
5th October
Review distribution
15th October
Revised paper submission
NOTE: All dates are in AoE timezone
Organisers
Student Coordinator
Contact us
Subscribe to our mailing list for the latest announcements and discussions.
For any queries write to us at hasoc@googlegroups.com