
HASOC (2022)
Hate Speech and Offensive Content Identification in English and Indo-Aryan Languages
Hate Speech and Offensive Content Identification in English and Indo-Aryan Languages
A conversational thread can also contain hate, offensive, and profane content, which is not apparent from a standalone or single tweet or comment or the reply to a comment, but can be identified if given the context of the parent content.
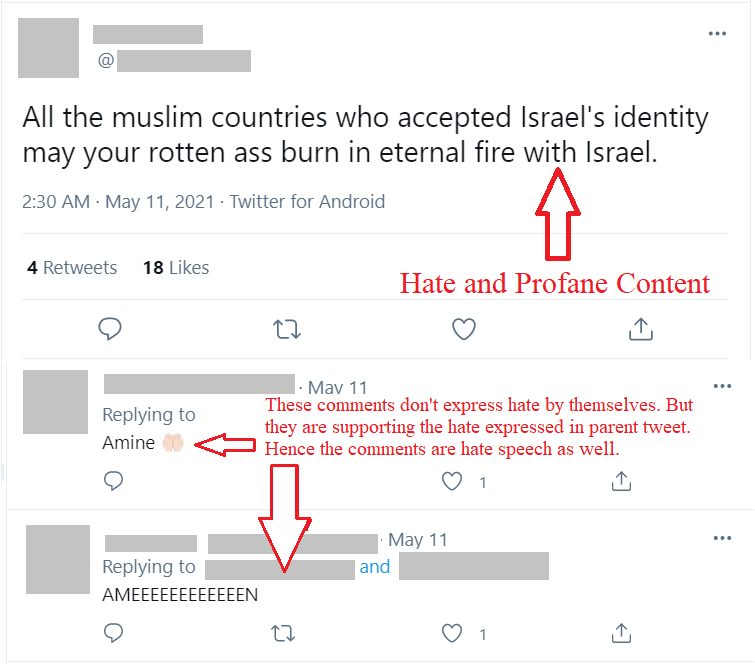
Example-1
The above screenshot from Twitter describes the problem at hand effectively. The parent/source tweet, which was posted at 2:30 am on May 11th, expresses hate and profanity towards Muslim countries regarding the controversy happening during the recent Israel-Palestine conflict. The 2 comments on the tweet have written "Amine", which means trustworthy or honest in Arabic. If the 2 comments were to be analyzed for hate or offensive speech without the context of the parent tweet, they wouldn’t be classified as hate or offensive content. But if we take the context of the conversation, then we can say that the comments support the hate/profanity expressed in the parent tweet. So those comments are labelled as hate/offensive/profane.
This sub-task focused on the binary classification (task 2) of such conversational tweets with tree-structured data into: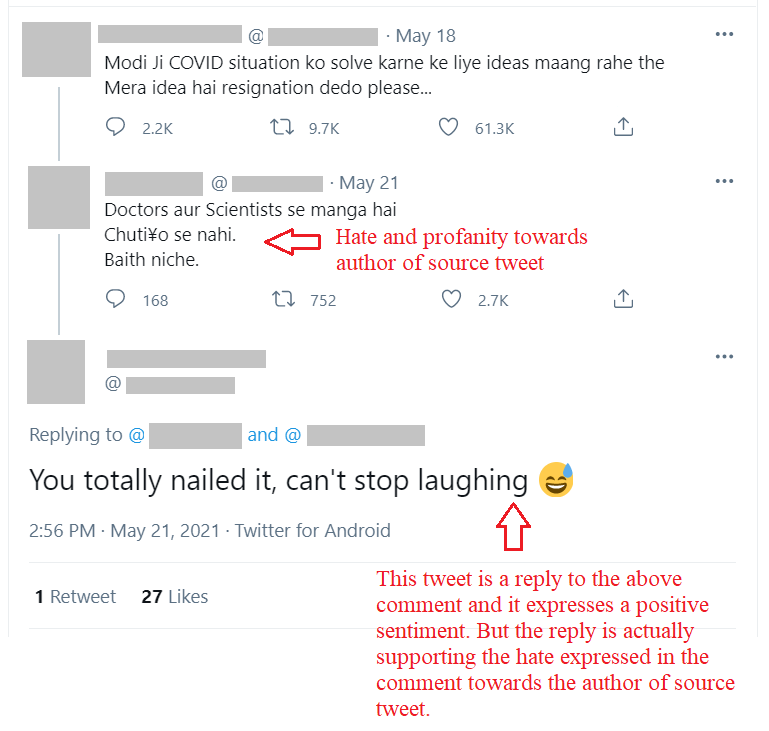
Example-2
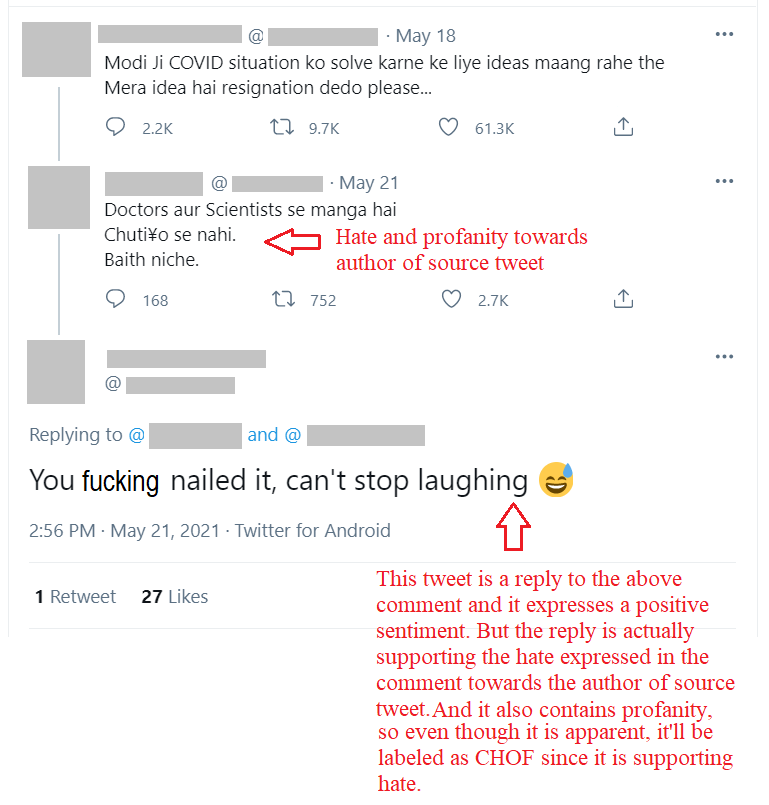
Example-3
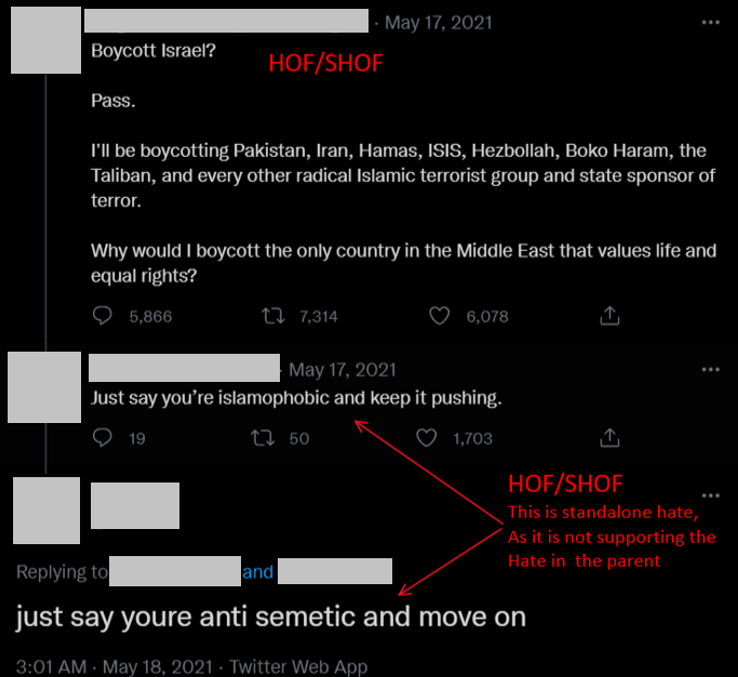
Example-4
In the above example-4, the main tweet portrays hate against a religion. Meanwhile, the comment is hateful against the author of the tweet. And not supporting the hate that was expressed in the main tweet. This is an example of 2 levels having standalone hate.
The sampling and annotation of social media conversation threads is very challenging. We have chosen controversial stories on diverse topics to minimize the effect of bias. We’ve hand picked controversial stories from the following topics that have a high probability of containing hate, offensive, and profane posts.
The controversial stories are as follow:
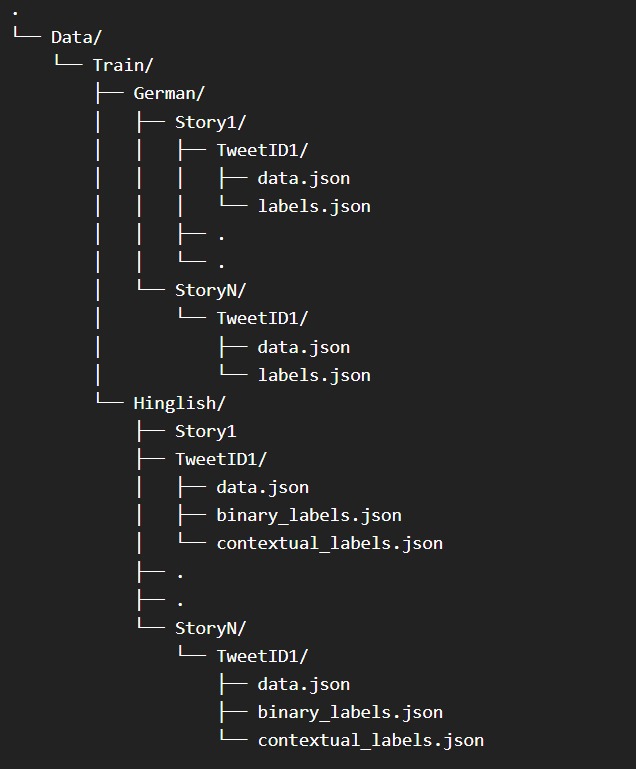
The directory structure of data directory :
The rectangles are keys and ovals are elements of array represented by the parent key.
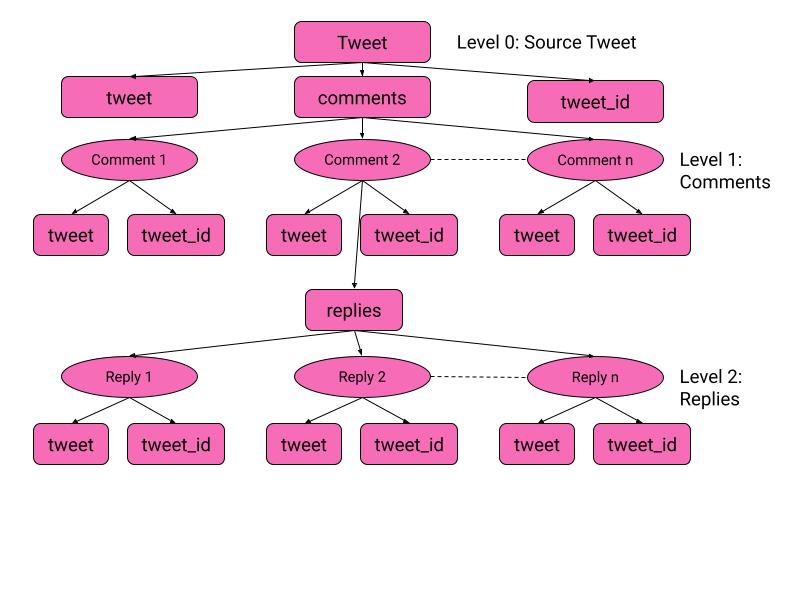
The structure of labels.json, binary_labels.json and contextual_labels.json is linear. They contain no nested data structure. They only contains key-value pairs where the key is the tweet id and value is the label for the tweet with the given tweet id. binary_labels.json in hinglish and labels.json german will be used for task-1(binary classification) and contextual_labels.json will be used for task-2(multi class classification).
Subscribe to our mailing list for the latest announcements and discussions.
For any queries write to us at hasoc2019@googlegroups.com