Task Description:
HASOC provides a forum and a data challenge for multilingual research on the
identification of problematic content. This year, we offer 3 tasks with a separate
dataset for all the tasks. All datasets are sampled from Twitter.
Task-1 is offered for Marathi with 1 problem. Task-2 contains two tasks namely: Task
2A offered in Hindi-English code-mix binary and Task 2B offered in German code-mix
binary. Task-3 is offered in Hindi-English code
mix multiclass. Participants in this year’s shared task can choose to participate in
one or two of the subtasks. Participants can look at the openly available data for
HASOC 2021, 2020 & 2019. To access data,
Click
Here.
Task 1: Identification of Conversational Hate-Speech in Code-Mixed Languages
(ICHCL) - Binary Classification.
A conversational thread can also contain hate and offensive content it which is not
apparent just from the single comment or the reply to comment but can be identified
if given the context of the parent content.
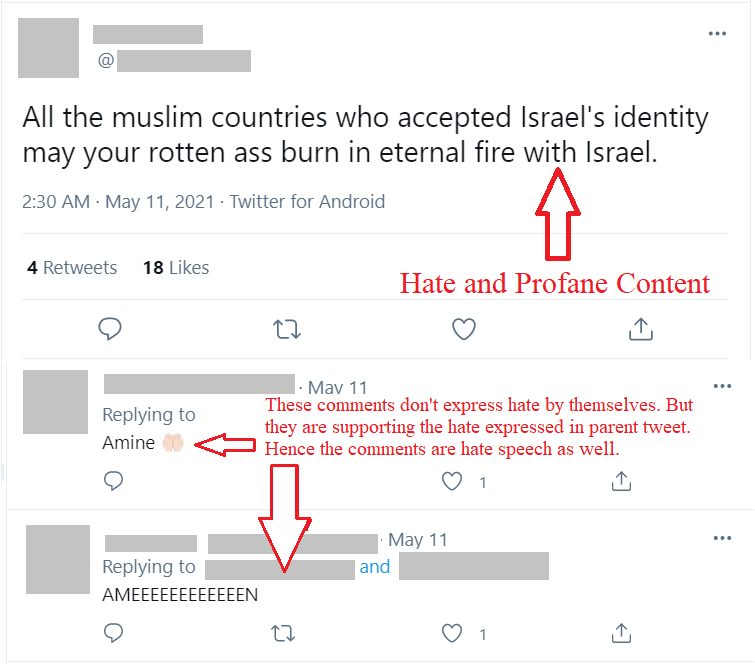
The parent tweet is expressing hate and profanity towards Muslim countries
regarding the controversy happening in Israel at the time. The 2 comments on the
tweet have written “Amine” which means "truthfully" in
Persian. Which is supporting the hate but with the context of the parent.
Task 1: ICHCL HINGLISH and GERMAN Codemix Binary Classification.
A task focused on hate speech and offensive language
identification is offered for Hinglish and German. It is a coarse-grained binary
classification in which participants are required to classify tweets
into two classes, namely: hate and offensive (HOF) and non- hate and offensive
(NOT).
- (NOT) Non Hate-Offensive - This post does not contain any Hate
speech, profane, offensive content.
- (HOF) Hate and Offensive - This post contains Hate, offensive, and
profane content.
Task 2: Identification of Conversational Hate-Speech in Code-Mixed
Languages (ICHCL) - Multiclass Classification.
A conversational thread can also contain hate and offensive content it which
is
not apparent just from the single comment or the reply to comment but can be
identified if given the context of the parent content.
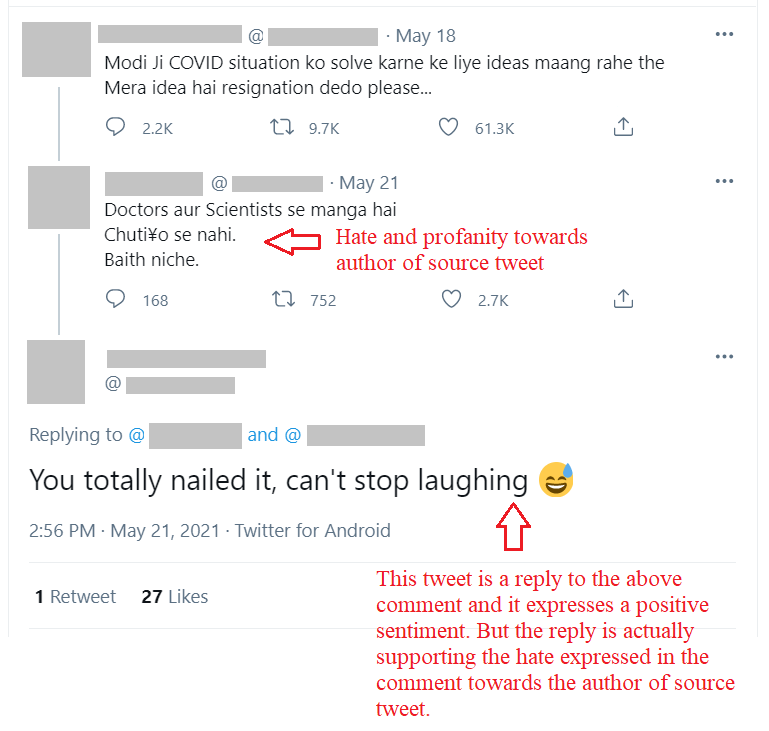
The reply has a positive sentiment. But it is positive in favour of the
hate expressed towards the author of the source tweet in the comment. Hence,
it
is supporting the hate expressed in the comment. Hence,
it is also hate speech.
This year for the Hinglish language, we’re introducing a
multiclass
task that further divides the HOF tweets into 3 subclasses:
- (SHOF) Standalone Hate - This tweet, comment, or reply
contains
Hate, offensive, and profane content in itself.
- (CHOF) Contextual Hate - Comment or reply is supporting the
hate,
offense and profanity expressed in its parent. This includes
affirming
the hate with positive sentiment and having apparent hate.
- (NONE) Non-Hate - This tweet, comment, or reply does not
contains
Hate, offensive, and profane content in itself.
For more info about task 1 and 2,
click
here
Task 3: Offensive Language Identification in Marathi
A task focused on hate speech and offensive language identification
is
offered for Marathi which follows
OLID texonomy that contains
collection of annoted
tweets that encompasses following three levels.
- Subtask-3A: Offensive Language Detection
In this subtask, the goal is
to
discriminate between offensive and non-offensive posts. Offensive posts include
insults, threats, and posts containing any form of
untargeted profanity. Each instance is assigned one of the following two labels
- OFF - Posts containing any form of non-acceptable language
(profanity) or a targeted offence, which can be veiled or direct.
- NOT - Posts that do not contain offence or profanity.
- Subtask-3B: Categorisation of Offensive Language
In subtask B, the
goal
is to predict the type of offence. Only posts labelled as Offensive (OFF) in
subtask
A are included in subtask B. The two categories
in subtask B are the following:
- Targeted Insult (TIN) - Posts containing an insult/threat to an
individual, group, or others.
- Untargeted (UNT) - Posts containing nontargeted profanity and
swearing.
- Subtask-3C: Offense Target Identification
Subtask C focuses on the
target
of offences. Only posts that are either insults or threats (TIN) are considered
in
this third layer of annotation. The three labels
in subtask C are the following:
- Individual (IND): - Posts targeting an individual.
- Group (GRP) - The target of these offensive posts is a group of
people considered as a unity due to the same ethnicity, gender or sexual
orientation, political affiliation, religious belief, or other
common characteristics.
- Other (OTH) - The target of these offensive posts does not belong
to
any of the previous two categories.
Contact us
Subscribe to our mailing list for
the
latest announcements and discussions.
For any queries write to us at hasoc@googlegroups.com